
背景
近几日,公司的应用团队反应业务系统突然变慢了,之前是一直比较正常。后与业务部门沟通了解详情,得知最近生意比较好,同时也在做大的促销活动,使得业务数据处理的量出现较大的增长,最终系统在处理时出现瓶颈。
分析和追踪问题的根源
首先:通过工具追踪服务器的性能,主要定位什么资源、在什么时候出现瓶颈。
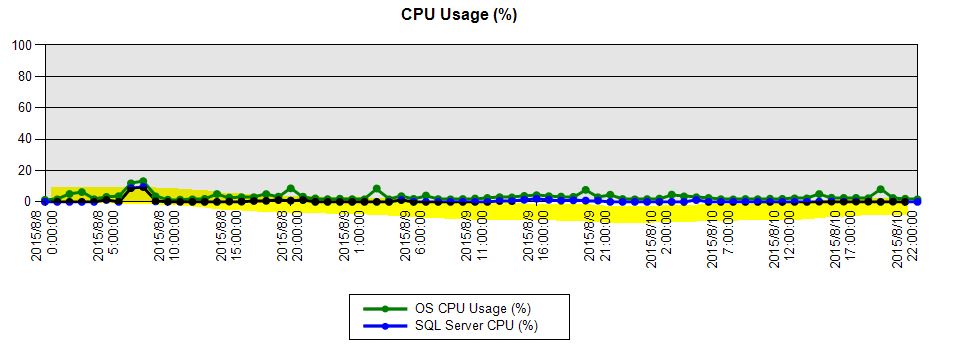
这样的工具很多,可以网上搜搜工具和使用方法如PerMon和PAL等,最终得到结果是在业务高峰期(中午12点到23点前)如下图,CPU资源使用率一直很高,初步可以判断是CPU资源紧张。那真的“资源”不够吗?!不一定,进一步分析。
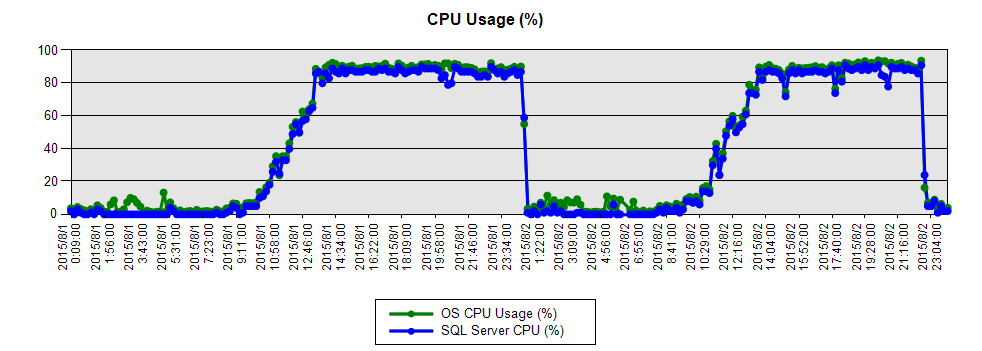
下一步,要更进一步实时监测到底什么东西在消耗CPU资源。
可以实时监控SQL Server资源的工具也很多,我这里使用的SQL Server Profiler,通过过滤和筛选相关Event后抓取想要的列,最主要是CPU这一列的值,如下:
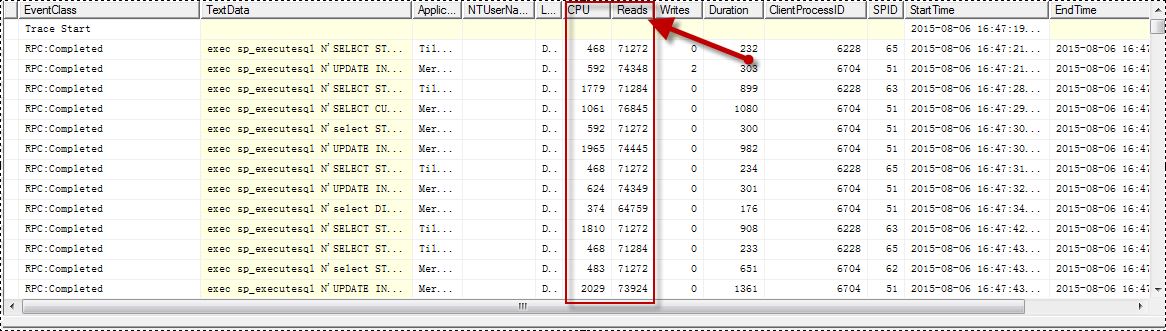
上图,查看每一列CPU资源使用情况,看起来是不是很累,还好有另外一个国外很好的工具ClearTrace,它可以很轻松地分析出trc文件中最占资源的如CPU/Reads/Writes等,这里重点分析CPU,如下图标出,第一二行就是导致CPU资源瓶颈的SQL语句
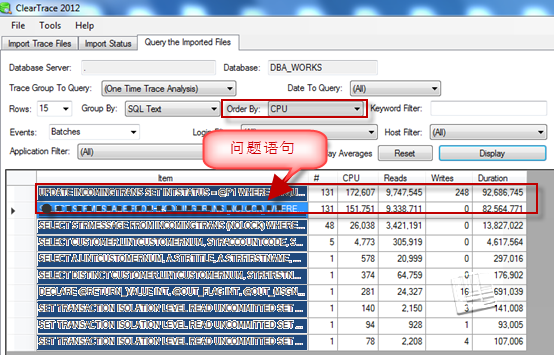
下一步,重点单独调试、分析上面列出的有问题语句。
我采用做法是将上面拷贝出来并填写对应条件参数的值,将整个语句拿到SSMS中单独调试,开启Actual Execution Plan和IO、Time统计,如下图显示单次执行logical read接近8.5w次,执行计划显示查找是通过索引扫描,这个表比较大,所以查询效率很低。而恰恰在这个案例中该语句执行频率极高,最终给资源特别是CPU造成很大损耗。
这里推荐大家另外一个不错的执行计划分析工具sqlsentry plan Explorer。
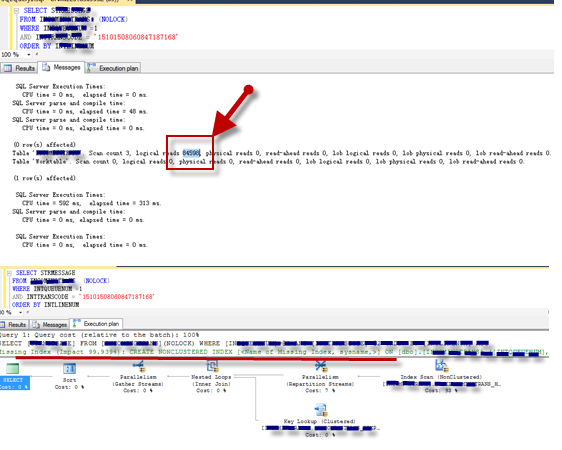
接下来,试着在QA环境中,根据语句条件加上合适的非聚集索引。
看一下效果如下图,logical reads降到个位数,加上非聚集索引后,执行计划走的Index Seek,查询效率极大提升。
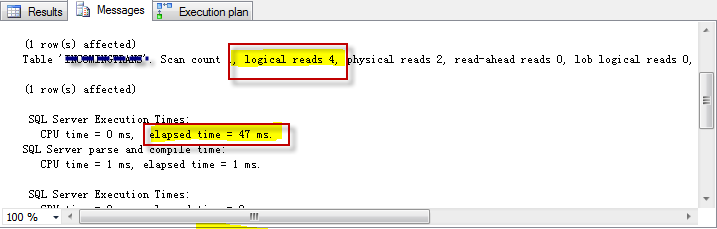
最后,实施到生产环境后,查看优化效果。
总结
很多时候,当我们遇到系统性能问题,需要先收集数据后,再通过数据分析确定问题根源。本案例在日常数据库运维中比较典型的,常规入手点就是检查PerfMon输出,已识别Memory、I/O 、CPU的瓶颈,资源瓶颈可能就是来自于某个或几个执行效率特别差的查询语句,经过适当的数据收集、分析处理基本可以锁定根源,并通过适当的方法如调整索引、调整语句写法等基本可以解决主要性能问题,特别是在系统上线不久这些问题尤为明显。另外就是随着时间推移,系统的业务压力增加,数据量增加也会带来类似性能问题。总的来说,建议一定要先从应用层面、数据库中索引、存储过程代码等最基本的方面入手进行调优,最大程度榨取提升性能的空间,然后再考虑数据库配置、硬件等。另外特别提醒,解决一个瓶颈可能带来另一个瓶颈,所以建议对调优的内容做一段时间的监控。



相关推荐
母婴依恋缺失的评估及修复指导案例分析,吕雪,马亚娜,文章以一混乱型母婴关系缺失亲子对的个体指导为例,按照母婴依恋关系缺失的评估及修复指导工作步骤,即信息整合、概念化与评估、
缺失值检测与处理案例.ipynb
跨国公司社会责任缺失案例.doc
wps for linux版本安装打开后会提示部分字体缺失问题,资源中包含所需要的全部6种字体:mtextra.ttf,symbol.ttf,WEBDINGS.TTF,wingding.ttf,WINGDNG2.ttf,WINGDNG3.ttf。下载解压后将其中的字体copy到/usr/share/...
LTE基站MR数据大量缺失问题处理案例.pdf
01.nodemanager资源总量配置问题--maven工程插件缺失问题.mp4
Python代码源码-实操案例-框架案例-空值、值等缺失值检测….zip
通过SAS宏程序,计算数据集中的每一个变量中的缺失值占变量中所有观测值得比例。
民营企业的人才瓶颈源于文化沟通机制的缺失.pdf
卫生部门可以使用这些洞察来组织心理咨询计划,提供对感到压力的人的一对一咨询。研究生可以使用这些数据来开展进一步的研究。一般公众可以检查可视化数据,以提供额外的支持和关心给他们的亲朋好友和家人。 主要...
同时还将演示当面对一个带有一些缺失标签的数据集时,如何将 GAN 用于半监督学习。许多研究人员认为无监督学习是一般 AI 系统中缺失的环节。为了克服这些障碍,尝试使用较少的标记数据来解决指定的问题是一个关键。...
资源内包含tableau模板源文件,文本说明,python脚本文件,有需要的可以自行下载
构建SR-A表达缺失自发性肥胖小鼠模型,朱旭冬,,目的:为了进一步研究SR-A在肥胖及其相关性疾病中的作用,需要构建SR-A表达缺失自发性肥胖小鼠。 方法:将SR-A+/+OB/ob和SR-A-/-小鼠进行�
1、资源内容:基于Matlab实现多个经典小波算法案例分析(源码+案例).rar 2、适用人群:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业或毕业设计中的部分功能,作为“参考资料”使用。 3、解压说明...
个人资源中DOA算法缺失的findpeak函数。下载后放到同级目录即可使用。此函数就是为了找到数组最大值对应的方位角。
含缺失数据的未决赔款准备金评估案例分析.docx
1. 通过补充缺失代码,完成一个 5 条指令单周期 CPU 的设计与验证; 2. 通过调试并修正已有实现中的错误,完成一个 20 条指令单周期 CPU 的设计与验证; 3. 在已实现的单周期 CPU 基础上,设计一个不考虑相关引发的...
检测统计缺失值并显示缺失值的个数
根据应急案例属性复杂及属性值缺失的问题设计了基于结构相似度和属性相似度双层结构的案例全局相似度计算算法,避免了传统最近相邻算法中的属性值缺失问题;最后通过基于案例推理的应急辅助决策原型系统的开发使设计...